
Seit dem Jahr 2011 wurde viel über das Thema "Termgewichtung" und "WDF * IDF" geschrieben. Das begrüße ich sehr, denn das Thema Keyword-Density gehört endgültig ausgerottet.
Der Schutz Deiner Daten ist mir wichtig!
Ich respektiere Deine Privatsphäre. Deshalb habe ich die Datenerfassung auf dieser Website auf ein Minimum reduziert.
Achtung: Wenn ich nicht weiß, was Du schon alles von mir kennst, zeige ich Dir möglicherweise lauter Zeug, das Du schon kennst. Das ist doof, weil es unnötig ist.
Wenn Du mir eine kleine Chance für das Tracking lässt, reduzierst Du für Dich unnötige Werbung - und ich kann meine Inhalte weiter verbessern! :-)
Klingt das nach einem guten Deal?
Hinweis: Diese Einstellungen kannst Du jederzeit auf der Datenschutz-Seite widerrufen.
In diesem Beitrag erhältst Du Hintergrundwissen rund um die Termgewichtung und lernst das Konzept WDF*IDF praxisnah kennen.
Um die Bedeutung in der täglichen SEO-Arbeit zu verstehen, empfehle ich Dir diesen Auszug aus der plentyShop Siteclinic. Ich gehe hier ganz direkt auf einige Aufgabenstellungen ein, die sich mit der Termgewichtung analysieren und lösen lassen:
Wenn Du noch tiefer in das Thema einsteigen möchtest, dann findest Du auf dieser Seite eine erste Heranführung an das Thema.
Wenn Du ein leistungsfähiges Termgewichtung-Tool suchst, dann hol Dir ein karlsCORE Konto und leg direkt los!
Am Anfang war ... das Dokument
Unsere kleine Geschichte beginnt mit einem HTML-Dokument. Du erstellst es, integrierst es in eine Website, verlinkst es sorgfältig und sorgst dafür, dass Suchmaschinen das Dokument finden können.

Und nach einer Weile stellst Du fest, dass das Dokument indexiert wurde und nun über Suchmaschinen gefunden wird. "Es rankt", wie der Suchmaschinenoptimierer zu sagen pflegt.
Wichtige Ranking-Faktoren
Es gibt eine große Anzahl wichtiger Faktoren, die das Ranking Deines Dokuments beeinflussen. Ein paar davon sind auf dem nächsten Bild aufgeführt.

- Informations-Architektur, in der Dein Dokument eingebettet ist
- Externe Verlinkungen, die auf Dein Dokument zeigen
- Das Besucherverhalten auf Deinem Dokument
- und viele mehr ...
Alle Rankingfaktoren sind ... manipulierbar.
Worauf soll man sich in diesem Leben eigentlich überhaupt noch verlassen? Wohin man schaut, wird manipuliert. Und in der Tat: Alle dieser Rankingfaktoren sind mehr oder weniger manipulierbar.
Und worauf kann man sich dann verlassen? Nun, zum Beispiel auf ein im Cache gespeichertes Dokument!
Die vertrauenswürdigste Datenbasis innnerhalb eines Information Retrieval Systems sind die darin enthaltenen Dokumente. Bei allen anderen Faktoren müssen wir davon ausgehen, dass sie mit hoher Wahrscheinlichkeit manipuliert werden.

Das ist eigentlich cool: Dokumente im eigenen Verfügungsbereich sind selbstbestimmte Objekte. Du steuerst die Güte Deine Dokumente direkt über Dein Investitionsverhalten. Spätestens jetzt erwacht der Suchmaschinenoptimierer in uns und fragt:
Moment mal - wie könnten wir die Termgewichtung manipulieren?
Die Frage ist nicht neu und es gab unzählige Versuche, die Termgewichtung mit Hilfe der Suchbegriff-Dichte (Keyword-Density) innerhalb eines Dokuments zu beschreiben.

Dass die Betrachtung über die Suchbegriff-Dichte mathematisch wie logisch völlig irreführend ist, habe ich im Artikel "Kill Keyword-Density" beschrieben.
Termgewichtung via WDF*IDF in einfachen Information Retrieval Systemen
Die Berechnung der Termgewichtung ist an und für sich gar keine allzu große Nummer. Schlägt man ein Buch zum Thema Information Retrieval auf, findet man oft genau diese kleine Formel:

Die Gewichtung eines Terms i in einem Dokument j lässt sich als Produkt aus der dokumentspezifischen Gewichtung des Terms innerhalb des Dokuments und der inversen Dokumenthäufigkeit des Terms i innerhalb eines definierten Dokumente-Korpus berechnen.
Soweit, so gut - was bedeutet das im Detail?
Bestimmung der dokumentspezifischen Termgewichtung über die Within-Document-Frequency
Die vereinfachte Formel zur Berechnung der Within-Document-Frequency sieht so aus:

Grundsätzlich ist die Within-Document-Frequency nichts anderes als die Keyword-Density, welche um einen Logarithmus zur Basis 2 versehen wurde. Dieser "Stauchung" ist der Natürlichkeit unserer Sprache geschuldet.
Die Within-Document-Frequency ist also der Quotient aus dem Logarithmus zur Basis 2 der Termfrequenz i und dem Logarithmus zur Basis 2 der Gesamtanzahl der vorkommenden Terme im Dokument j.
Wichtig:Diese Berechnung ist vom Funktionsprinzip her gültig, liefert jedoch fehlerhafte Werte. Auf die genauere (richtigere) Bestimmung gehe ich im Laufe dieses Dokuments noch ein.
Und die Inverse-Document-Frequency (IDF)?
Wenn es innerhalb eines Information Retrieval Systems nur ein einziges Dokument gäbe, liesse sich das unmissverständlichste Term-Signal das Dokument durchaus über die Keyword-Density und einem Hasenstall an Stop-Begriffen ermitteln. Leider Gottes ist unser Dokument nicht alleine im Index. Im Gegenteil: Es gibt verdammt viele Dokumente im WWW.

Um die Gewichtung eines Terms in unserem Dokument innerhalb eines Information Retrieval Systems zu ermitteln, müssen wir es also in Relation zu allen anderen Dokumenten im Index setzen:

Schlägt man ein Lehrbuch auf, wird die Inverse-Document-Frequency IDF(i) aus dem Logarithmus zur Basis 10 des Quotienten aus dem Dokumentenkorpus N(D) und der Menge der Dokumente N(i) gebildet, wobei N(i) die Anzahl der Dokumente ist, die den Term i enthalten.
Wer bis hierher aufmerksam war, legt jetzt die Stirn in Falten und fragt ....
Aber wie berechne ich den Dokumentenkorpus N(D)?
Diese Frage ist berechtigt. Es gibt zwei wesentliche Ansätze, den einfacheren möchte ich hier darstellen.
Wichtig: Wer auf dieser Basis ein Werkzeug entwickelt, sollte sich mit der Thematik wirklich intensiv auseinandersetzen. Ich erläutere hier Funktionsprinzipien, keine belastbaren Formeln für den perfekten, direkten Einsatz ... ;-)
Für die Ermittlung des Dokumentenkorpus N(D) stellen wir fest, dass es im Suchmaschinenindex für jeden Term i aus unserem Dokument j eine gewisse Menge an Resultaten gibt:

Diese Betrachtung muss folgerichtig für jeden einzelnen Term i aus unserem Dokument j durchgeführt werden: Sobald unser Dokument einen Term i enthält, "misst" sich unser Dokument mit n Suchmaschinenresultaten, d.h. Dokumente, die diesen Term ebenfalls enthalten.

Aus der Summe aller Suchmaschinenresultate lässt sich somit der Dokumentenkorpus N(D) bilden:

Zusammenfassend und stark vereinfacht gesagt ist der Dokumentenkorpus N(D) die Summe aller Suchmaschinenresultate für alle Terme innerhalb eines Dokuments.
In dieser Grafik wird noch die Formel dargestellt:

Im nächsten Schritt können wir nun die Detail-Berechnungen für die Within-Document-Frequency (WDF) und die Inverse-Document-Frequency (IDF) in unsere Formel einsetzen.
Berechnung der Termgewichtung w=wdf*idf mit dieser Formel
Unsere Termgewichtung für jeden Term i innerhalb unseres Dokuments kann also wie folgt berechnet werden:

Sieht noch nicht einmal so wild aus. Das spannende an der Sache ist: Bereits diese a) fehlerhafte und b) stark vereinfachte Berechnungsmethode liefert erstaunliche Resultate. So konnten in der Praxis viele hunderte Beispiele für ein sogenanntes "Linkless Outranking" erzielt werden. Dabei ist weniger die Rede von Longtail-Begriffen, sondern eher "harten Money-Keywords" wie zum Beispiel "Landingpage".
STOP. Bitte weiterdenken.
Die Berechnung und Methodik endet hier noch lange nicht. Wer ein klein wenig weiterdenkt, findet weitere Feinheiten, die ebenfalls bedacht werden müssen:

So ist die Ermittlung der Within-Document-Frequency (WDF) eigentlich grundsätzlich falsch, wenn der zu betrachtende Term nicht aus der Gesamtmenge der Terme eines Dokuments herausgenommen wird (siehe veränderte Berechnung des WDF).
Und auch eine einfache Summenbildung beim Dokumentkorpus N(D) ist nicht wirklich das Gelbe vom Ei. Innerhalb der ermittelten Suchmaschinenresultate können natürlich auch andere Terme aus unserem Dokument j vorkommen. Das bedeutet, dass hier die Berechnung der Vereinigungsmenge erforderlich ist.
Und so weiter ... und so fort.
Wichtig:Spätestens bei dem Begriff "Vereinigungsmenge" sollte jeder kurz zusammenzucken und feststellen, dass eigentlich kein kleiner bzw. mittelgroßer Anbieter von Analyse-Werkzeugen eine derartige Berechnung für eine große Anzahl an Benutzern anbieten kann ... ;-)
Alter Wein in alten Schläuchen
Prof. Mario Fischer hat in einem Kommentar angemerkt, dass dieser "Alte Wein" noch nicht mal aus einem neuen Schlauch kommt. Richtig. Das Funktionsprinzip gibt es schon seit ein paar Jahren:

Die Recherchen reichten bis in das Jahr 1972 zurück ... bereits damals beschäftigte sich Sparck Jones mit der Thematik.
Und ich frage jetzt allen Ernstes: Was machen wir mit SEOs, die immer noch etwas von absoluten Werten der Keyword-Density erzählen?
Hinweis für die Anbieter von Analyse-Werkzeugen. Und für deren Nutzer.
Selbst die "feinere" Berechnungsformel genügt für die Praxis noch nicht:

Sonderthemen wie Sprachen, Behandlung von Synonymen, Proximity / Anti-Proximity und noch vieles mehr gehört ebenfalls mit in eine ordentliche Betrachtung.
Benutzer von Analyse-Werkzeugen für die Termgewichtung sollten also mindestens folgende Fragen stellen:
- Auf welche Art und Weise wird der Dokumentenkorpus berechnet?
- Was soll das bescheuerte "P" in der Formel?
- Welche weiterführenden Berechnungen werden durchgeführt und wie funktionieren diese?
Dieses Video der OMCap zeigt ein paar Ausschnitte aus den Erläuterungen inklusive der Tonspur:
So. Wenn Du wirklich bis hierher gelesen hast, dann sage ich "Hut ab"! Jetzt ist auch mal gut mit der trockenen Theorie. Schauen wir uns an, was diese Berechnung der Termgewichtung für die Praxis bedeutet:
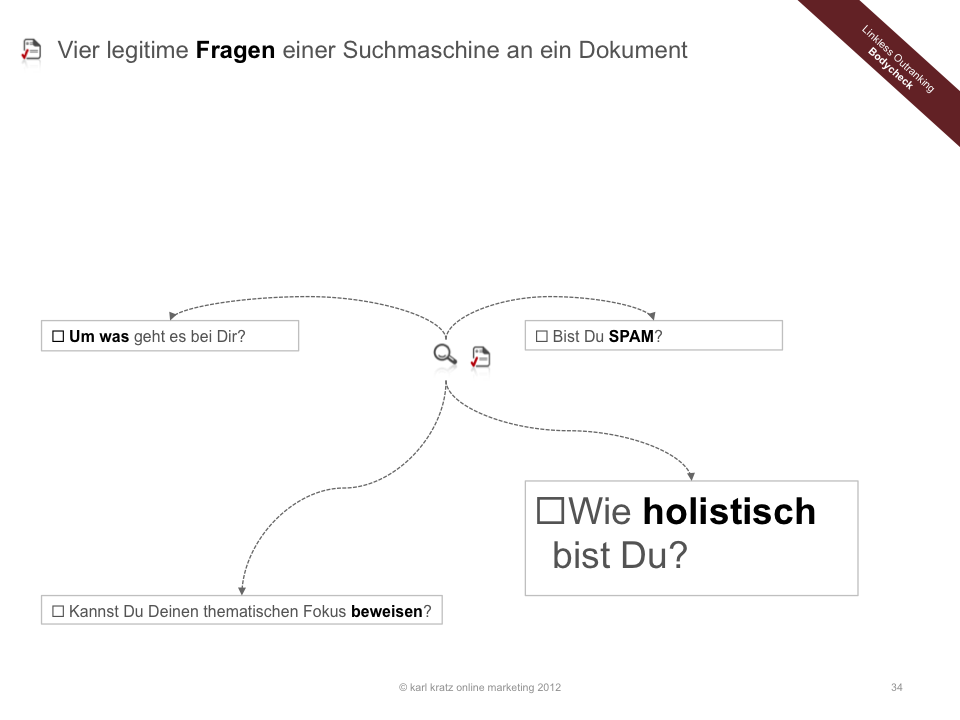
Fragen, die eine Suchmaschine einem Dokument stellen sollte, kann und wird.
Stelle Dir vor, Du bist eine Suchmaschine. Es klopft an der Tür und ein Dokument steht davor. Was wäre Deine erste Frage? Vielleicht: "Ja, bitte? Wer bist Du denn?
Um was geht es bei Dir? Was ist Dein unmissverständlichstes Term-Signal?

Bist Du SPAM?
Zurück zu unserer Funktion als Suchmaschine. Vor uns steht dieses Dokument, das von sich behauptet "dass es um Risikolebensversicherung geht". Du hast eine Analyse der Termgewichtungen durchgeführt und festgestellt, dass das erst einmal stimmt. Gibt einen Pluspunkt.

Unsere nächste Frage an das Dokument sollte sein: Bist Du Spam? Es gibt verdammt viele Dokumente im Index, die sich mit dem Thema beschäftigen. Und der allergrößte Teil dieser Dokumente ist MIST. Zusammengescrapter digitaler Vollschrott, Keyword-Stuffing par excellence, Content-Spinning-Scheiss. So, ich bitte vielmals um Entschuldigung und hoffe, dass bis hierher ohnehin keiner mehr liest. ;-)
Die Frage nach dem "Spamlevel" ist aus Suchmaschinensicht also durchaus legitim: Wer aus der Reihe tanzt, fliegt. Es ist also das bewährte Kollektiv gefragt. Es ist betriebswirtschaftlich eine kostengünstige Methode, um eine relativ sichere Aussage zu erhalten.
Mit dieser Betrachtung erhalten wir einen termspezifischen, durch das Kollektiv definierten und von der Suchmaschine als gültig etablierten, Spam-Level auf Termgewichtungs-Ebene. Dokumente, deren Termgewichtungen oberhalb dieser "Hüllkurve" stattfinden, sind per Definition also erst einmal Spam - oder haben mit dem unmissverständlichsten Signal nicht wirklich viel zu tun.
Für OnPage.org-Nutzer: Es macht durchaus Sinn Terme innerhalb eines Dokuments abzuschwächen um innerhalb des Spam-Levels zu bleiben. In der Praxis sorgte das oft genug dafür, dass ein Dokument (meist erstmalig) in den jeweiligen Ranking-Abfragen zu finden war.
Kannst Du beweisen, um was es bei Dir geht?
So, wieder zurück zum Thema: Du bist eine Suchmaschine. Vor Dir steht dieses Dokument. Es sagt: "Bei mir geht es um Risikolebensversicherung" und beweist das auch. Andere, die das nicht beweisen konnten, hast Du erstmal wieder in die Warteschlange gestellt.
Das Dokument beweist auch, dass es sich artig "ungefähr so wie die anderen guten Dokumente verhält". Es kommen keine Terme übermäßig oder im Missverhältnis vor. Scheint also kein Spam zu sein.
Du ziehst eine Augenbraue hoch und fragst also als nächstes:

Liebes Dokument, kannst Du durch Dich selbst Dein unmissverständlichstes Signal beweisen?
Die Ermittlung solcher Terme für den Selbstbeweis (auch "Proof-Keywords") kann durch einen mathematischen Filter auf ein kollektiv aus Termgewichtungen über eine definierte Anzahl an sehr guten Ranking-Ergebnissen erfolgen.
Wie unterschiedlich bist Du?
So, wir fassen nochmal kurz zusammen:
- Du bist die Suchmaschine. Tür auf. Dokument steht da.
- Dokument sagt: "Bei mir geht es um xy." Du schaust Dir das unmissverständlichste Termsignal an.
- Dokument sagt: "Ich bin kein Spam. Ne, ne." Du schaust Dir an, ob die Terme des Dokuments innerhalb des Spam-Levels liegt, welches durch die Dokumente definiert wird, die bereits in einer exzellenten Ranking-Position sind.
- Dokument sagt: "Bei mir geht es um Risikolebensversicherung. Und um Absicherung. Und Versicherungssumme. Und die Hinterbliebenen." Andere Dokumente erzählen hier etwas von "Zahnrad", "Gummipuppe" und "Kinderüberraschung". Es scheint in dem Dokument wirklich um eine Risikolebensversicherung zu gehen.
Sehr schön. Dann fehlt doch eigentlich nur noch eine Frage: Gibt es eine Eintrittskarte für die Top-10?
Wenn ein Suchmaschinen-Benutzer eine Abfrage für einen relativ generischen Term in einer Suchmaschine startet, kann der Suchmaschinenbetreiber regelmäßig nur raten, was den Suchmaschinen-Benutzer interessiert.
Aus diesem Grund macht es durchaus Sinn, auf der ersten Seite eine Sammlung von Dokumenten zu präsentieren, die sich mit den unterschiedlichsten Perspektiven zum gesuchten Thema auseinandersetzen. Vor einiger Zeit habe ich die Hypothese aufgestellt:"Ändert sich unsere Perspektive auf ein Thema, ändert sich regelmäßig unsere Terminologie." In den vielen darauffolgenden (Massen-)Tests kam dabei eine spannende Erkenntnis heraus:
Thematische Unterschiedlichkeit (Diversity) ist messbar.
Wie wir die Termgewichtung für die Suchmaschinenoptimierung nutzen können
Du erinnerst Dich noch an das Dokument vor Deiner Tür? Wenn es diese vier grundlegenden Faktoren erfüllt, hast Du ONPAGE bereits eine sehr gute Basis geschaffen. Den Rest prügelst Du einfach dumpf mit Links tot.

Achte bei Deinen Inhalten auf
- ein eindeutiges, unmissverständliches Term-Signal
- die Einhaltung von Termgewichtungen, wie sie bei "den besten" Dokumenten vorkommen
- den Selbstbeweis, wie er bei "den besten" Dokumenten vorkommt und
- ein hohes Maß an Holismus, inhaltlichem Reichtum, dissonanten, kontroversen und extrem detailreichen Inhalten.
Final kann ich dazu nur sagen: Liebe Deinen Texter. Lass ihn die geilsten Texte überhaupt schreiben und bezahle ihn dafür königlich. Denn Deine Online-Texte sind mit das wertvollste, selbstbestimmte Asset, über das Du überhaupt verfügen kannst.
Hinweis: Du findest ein exzellentes WDF-IDF-Termgewichtungs-Werkzeug in karlsCORE public.
HINWEIS: DON'T TRY THIS AT HOME.
Nicht dieser Text legt fest, was Du liest. Du selbst legst fest, was Du liest. Ich bin zwar dafür verantwortlich, dass hier kein grober Unfug steht. Ich bin aber nicht dafür verantwortlich für das, was Du aus diesem Text liest ;-)
Dieser Artikel beschäftigt sich mit einem einzigen Ranking-Signal.